使用InfluxDB IOx跟踪
通过杰森·迈尔斯雅各大理石/ 2022年11月30日InfluxDB IOx,社区
跟踪一直是时间序列数据的一个关键用例。但不可否认的是,过去的InfluxDB版本也不能像我们想要的那样处理这个问题。其中一个障碍是基数问题。跟踪数据,几乎从定义上讲,是高基数的数据InfluxDB IOx,高基数数据可能会影响查询性能。
InfluxDB IOx消除了对基数的限制,从而开放了InfluxDB平台,以高性能的方式处理更广泛的用例,如跟踪和日志。因此,让我们来回答一些关于跟踪的基本问题,并说明InfluxDB IOx是如何实现跟踪的。
什么是跟踪?
当你有一个分布式系统时,一般来说,你想知道所有不同的组件是如何相互作用的。有些流程和服务可能依赖于其他流程和服务,因此错误、延迟和瓶颈会影响整个系统性能。
为了理解所有这些不同的部分是如何相互协调工作的,我们使用了一种称为跟踪的可观察性形式。当请求、任务、操作、作业或其他有用的工作单元在分布式系统中运行时,跟踪提供了它的视图。任意数量的子任务(算法、网络调用、数据库事务、缓存查询等)协调以满足请求。每个子任务都是一个span。
因此,跟踪是一组跨度的集合,它提供了关于请求更精细细节的计时信息。
跟踪是如何工作的?
跨度有0到多个子跨度,称为子跨度或子跨度。子span可以有自己的子span,等等。
跟踪从根跨度开始,没有父跨度。因为根跨度是跟踪中所有其他跨度的递归父跨度,所以根跨度的持续时间表示跟踪的总时间。
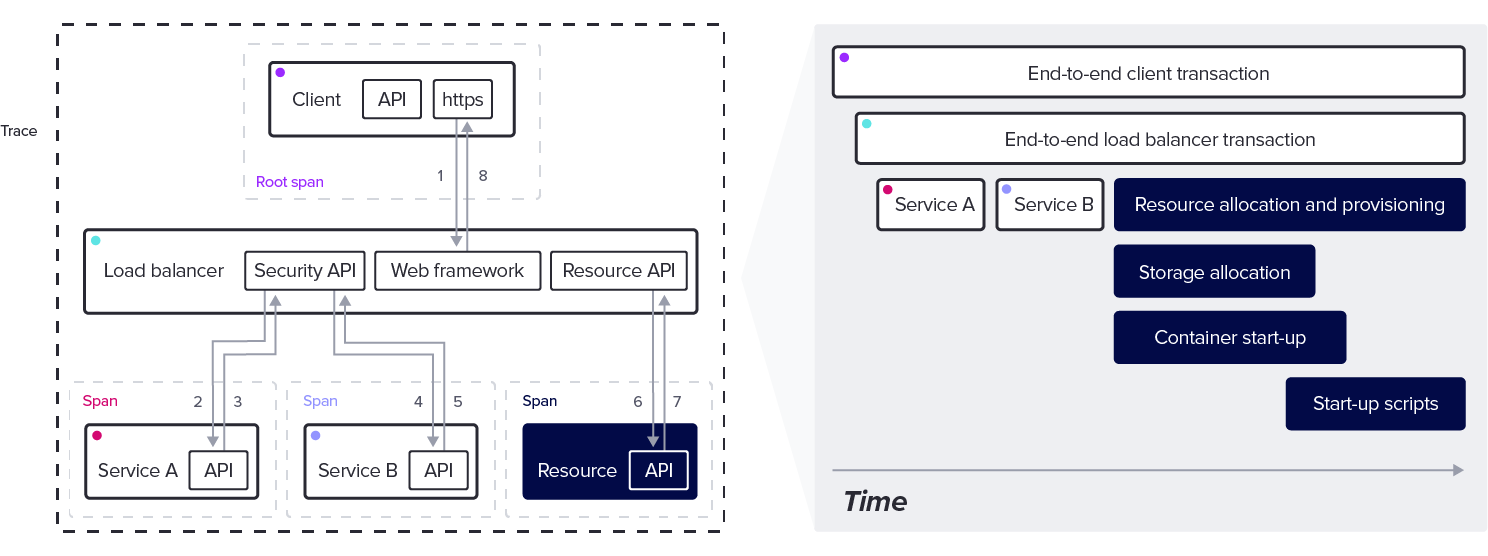
如图所示,在单个轨迹中有许多潜在跨度。
要从所有这些跨度构建跟踪,并确保所有内容正确地组合在一起,每个跨度都需要标识信息。为此,每个span都有一个跟踪ID、一个span ID,如果适用的话,还有一个父span ID。
这些构建块创建子任务的层次树,这些子任务为构建跟踪提供了关键结构。
这和基数有什么关系?
在IOx之前,InfluxDB的时间序列合并树(TSM)储存在系列列.系列是测量、标签和一个字段的唯一组合。在这个模型中,基数是系列的总数,即存储在磁盘上的列的数量。所以,如果你有两个级数,你的基数就是2。高基数通常会带来麻烦,因为它与较慢的查询性能相关。
为了避免在pre-IOx InfluxDB中失控的基数,序列的数量必须是有界的。跟踪的挑战在于每个跟踪和跨度生成一个唯一的ID(对于跟踪,大多数数据库模式将这些ID视为标记),从而创建无限的标记值。将此与跟踪数据的数量和速度结合起来,您将得到失控的基数。
IOx:解基数
以前版本的InfluxDB将每个系列存储为一个列,这可能导致有很多列。随着InfluxDB IOx的引入,度量时间戳、标记和字段都被保存到各自的列中,因此具有两个标记键和三个字段的度量用六列表示。这种设计极大地减少了数据库必须处理的列的数量。
类中存储表的列拼花文件。当更多数据到达时,IOx将表中的这些列写到一个新的Parquet文件中。Parquet文件可以很好地压缩数据列,IOx将这些文件存储在对象存储(S3)中,这是非常可伸缩的。InfluxDB云查询层会自动扩展您的查询工作负载。
Parquet文件格式还提供了出色的查询性能。例如,当IOx向Parquet写入数据列时,它在Parquet元数据中包含了描述列内容的提示。这样,查询引擎可以在查询时跳过整个Parquet文件和/或Parquet文件中无用的部分。
这些对InfluxDB存储引擎、持久性格式以及存储和查询层的更新结合起来提供了无限的基数,并解锁了跟踪等用例。
要开始使用InfluxDB IOx并查看可以为您解锁哪些无限基数,请注册InfluxDB IOx测试程序.